Run Your Own Coding Agent on Your Laptop (for Free)
Try Text
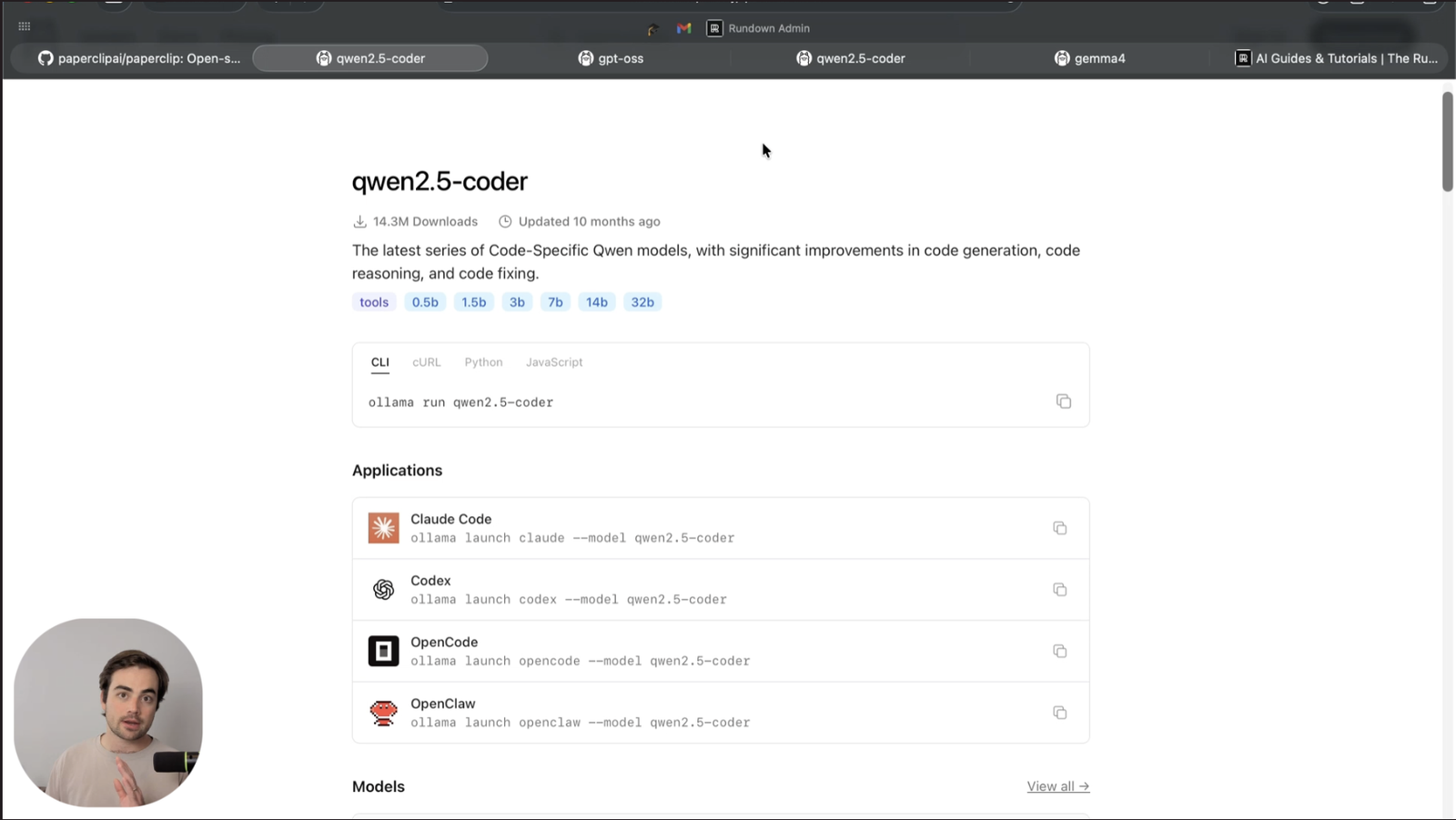
This guide teaches you how to download a coding LLM to your laptop with Ollama and wire it into Claude Code or Codex with a single command. You will end up with a local coding agent that can handle simple tasks for free while keeping proprietary code on your machine.

Save 15% on Thoughtly by joining The Runway University
Through our vast network of over 100 partnerships with major AI companies, we also offer University members free access or major discounts to the many popular AI tools along with AI certified courses, daily guides on AI tools and many more.
Tools
No items found.




AI training for the future of work.
Get access to all our AI courses, hundreds of real-world AI use cases, live expert-led workshops, an exclusive network of AI early adopters, and more.